Kurtenbach, G., Moran, T. & Buxton, W. (1994). Contextural animation of gestural commands. Proceedings of Graphics Interface '94, 83-90.
Contextual Animation of Gestural Commands
Gordon Kurtenbach+, Thomas P. Moran+ and William Buxton+++Xerox Palo Alto Research Center
3333 Coyote Hill Rd.
Palo Alto CA 94304
(415) 812-4753, kurtenba@parc.xerox.com
(415) 812-4351, moran@parc.xerox.com+Dept. of Computer Science++University of Toronto
Toronto, Ontario Canada, M5S 1A1
(416) 978-6619 willy@dgp.toronto.edu
Abstract
Drawing a mark can be an efficient command input technique when using a pen-based computer. However, marks are not intrinsically self-explanatory as are other interactive techniques such as buttons and menus. We present design principles for interaction mechanisms which make marks self explanatory for novices but still allow experts to use efficient command marks. The key notion is that use of the explanation mechanism physically trains a novice to use the efficient command marks. Two novel interaction mechanisms we have developed using these principles are presented.Keywords: pen input, gestures, marks, animation
INTRODUCTION DESIGN PRINCIPLES MARKING MENUS THE CRIB/SHEET ANIMATOR Problems with the marking menu approach Solutions Implementation Usage experiences FUTURE WORK SUMMARY & CONCLUSIONS ACKNOWLEDGMENTS
REFERENCES
It would seem that gestures would be easy to learn and use. However, one needs only to use any of the current crop of pen-based computers to experience serious difficulties. Recently, we assessed a new, sophisticated note-taking application that was touted as being natural and easy (and, in the press, as a real breakthrough in pen computing). When we sat down to learn and use the system, we expected it to be easy. After only a short while we found ourselves asking questions like: "What gesture do I make to undo something?" "Are there commands available with gestures that are not in the menus?" "Why isn't it interpreting my X-gesture as a delete gesture?" "Does it understand the standard proofreading marks?"
This situation is reminiscent of old-fashioned textual command language interfaces, such as the UNIX shell or MS-DOS, where the user is confronted with analogous questions. Thus, the issues behind the questions seem to be general to all command languages, be they textual or iconic:
Functionality - What functions does the system provide (in the form of commands)?
Naming - Given a function, what is the name or shape of the command (so that it can be issued)?
Context - Given a command, when and where in the system is it available to be used?
Method - How are the various arguments of a command specified (so that it can be applied to specific material in a specific way)?
There are several different strategies that the user can employ to answer these questions. Let us consider three: training, guessing, and learning-by-doing.
Training Strategy - The user can set aside a chunk of time to learn the system--take a course, read the manual, follow an on-line tutorial, etc. One problem with this strategy is that it is not tied to any particular task the user needs to do. During training, the user, in effect, memorizes the system ahead of time. Later, when it is time to do a particular task, the user may have forgotten many of the crucial details and will end up posing the same questions anyway. The goal of most pen-based systems is to be "natural" so as not require up-front training, the ideal being that one can just "walk up and use" them. We want to minimize the need for training.
Guessing Strategy - The user can forego training and just guess how to issue commands. This depends on the commands being mnemonic. For verbal commands, it has been shown that mnemonics are unreliable; command naming behavior of individuals is extremely variable (Carroll, 1985). But gestures are supposed to be intuitive and/or familiar. Many researchers have argued that users commonly agree on certain gestures for certain operations (Wolf, 1986; Gould, & Salaun, 1987; Buxton, 1990). However, beyond a small set of common operations (e.g. select, delete, move), there are few common conventions (mainly because gestural systems are so new). Thus, guessing by itself is inadequate.
Learning-While-Doing Strategy - A broader strategy is for the user to seek help in various ways while doing particular tasks and, in the process, learn more and more about the system . Thus the need for (and time taken in) seeking help is continually reduced. The critical thing to make this work is to minimize the amount of attention the user has to divert from the performance of the task in order to seek help (training and guessing are at the two extremes).
We can view many interface techniques of modern graphical user interfaces as supporting a learning-while-doing strategy. Menus of commands and panels of buttons and icons tell the user what functions are available and directly provide the means to invoke them. They allow users to recognize functions rather than having to recall them from memory. Two examples are menus and dialog boxes. Menus that pop up when certain objects are selected and pull-down menus with grayed out items show users the context in which commands are available. Dialog boxes give users simple methods for specifying parameters to commands.
What we propose is to extend these graphical user interface techniques with two specific goals in mind: (1) supporting the process of learning-while-doing and (2) dealing with the particular features of gestural commands. A couple of examples: We will consider techniques for inducing rehearsal, which is important to amplify the learning process. Gestures have the feature that they are drawn within the materials they are operating on (whereas textual commands, including menus, are issued from outside of the materials). Thus we have to provide guidance for how to draw gestures within the spatial context of the current materials. In this paper we define three user-interface design principles to support interactively learning and using gestures. We then describe two interaction techniques we have developed based on these design principles. The first technique supports learning and using the subclass of zig-zag-shaped gestures. The second technique deals with the general case of learning and using arbitrary-shaped gestures.
Revelation - The system should interactively reveal information about what commands are available and how to invoke them.
Gestures are not revealed because the user must recall them from memory. Menus and buttons, however, reveal the function and names of commands. They do not reveal the method for issuing the command. What menu systems do is to provide a common set of general methods (such as pointing, dragging, double clicking), which must be learned a priori. The Macintosh computer, for example, uses this technique. The intention is that with this small set of skills a user can start interactively exploring and learning about the remainder of the system.
The interaction techniques described in this paper use this type of design. A user must be informed, a priori, that in order to reveal the commands associated with an object the pen must be pressed over an object and held still for a fraction of second. We call this "press and wait for more information." Once users know this, they can get further instructions interactively from the system. This allows users to interactively learn about what functions can be applied to various displayed objects by pressing and waiting on the objects for menus.
Guidance - The way in which revelation occurs should guide a user through the method for specifying the complete command in any specific situation.
An example is selection from a hierarchic menu. In this case, selecting an item guides a user to the next menu. The critical point in these systems is that getting guidance on how to specify a command does not interrupt the specification process. On the other hand, a system like the on-line manual pages in UNIX violates the principle of guidance, because the user must terminate or at least suspend the act of specifying the command in order to get help.
Rehearsal - The way guidance is provided should require a physical rehearsal of the way an expert would issue the command.
The goal of rehearsal is to develop expert skills in a novice, in order to support the efficient transition from novice to expert performance. Many interaction techniques support rehearsal. When the action of the novice and the expert are the same for a particular function, we can say that rehearsal takes place. For example, novices may draw lines, move icons, or select from menus using the same actions as an expert when there is one and only one way of issuing the command. In many cases, the single way of issuing the command may be suitable for both the novice and expert.
There are also many situations, however, where a single method for invoking a command is not sufficient. The popularity of "accelerator techniques" is proof of this. Typically, interfaces provide two modes of operation. The first mode, designed for novices, is revealing. Conventional menu-driven interactions are an example of this. The revealing component of this mode is emphasized over efficiency of interaction, because novices are more concerned with how to do things rather than how quickly things can be done. The second mode, designed for experts, typically allows terse, non-prompted interactions. Command-line interfaces and accelerator keys are examples of this mode. However, usually there is a dramatic difference between novice and expert behavior at the level of physical action. For example, a novice uses the mouse to select from a menu whereas an expert presses an accelerator key. Thus, in these cases novice actions are not a rehearsal for expert performance.
It is critical that rehearsal be unavoidable. For example, the Macintosh supports novices by providing menus and supports experts by providing menu accelerator keys. The transition between novice and user is supported by having the names of the accelerator keys appear next to menu items in the menu. However, actually using an accelerator key is avoidable. The user can always just select from the menu. Furthermore, this is easiest because the user is already displaying the menu. The end result is that accelerator keys are sometimes not used even after extensive exposure to the menu. Our principle of rehearsal is intended remedy these situations.
The intention of the three design principles is to reduce this discrepancy in action without reducing the efficiency of the expert and ease of learning for the novice. The basic actions of the novice and expert should be the same. It is hoped that as novice performance develops the skills that lead to expert performance will develop in a smooth and direct manner. We next describe two interaction techniques that apply the design principles to gestures.
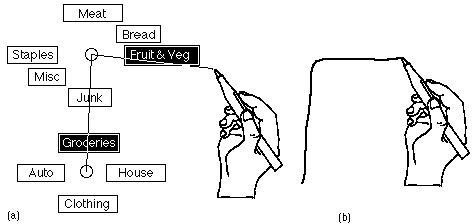
Figure 1: Marking menus permit two different ways to select menu items. Using method (a), hierarchic radial menus can be sequentially displayed and selections made. Method (b) uses a mark (gesture) to make the same selection.
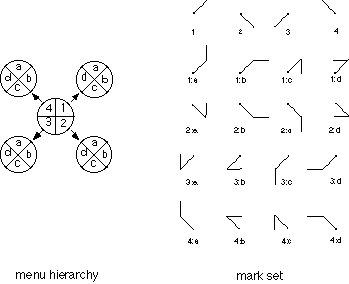
Figure 2: An example of a radial menu hierarchy and the marks that select from it. Each item in the numeric menu has a submenu consisting of the items a, b, c and d. A mark's label indicates the menu items it selects. A dot indicates the starting point of a mark.
With this goal in mind we developed an interaction technique called
marking
menus. Marking menus provide revelation, guidance, and rehearsal for
zig-zag types of gestures. This is done by integrating pop-up radial menus
and zig-zag gestures. In effect, zig-zag gestures are the byproduct of
selection from radial menus. This works as follows: A novice user presses
down on the screen with the pen and waits for a short interval of time
(approximately 1/3 second). A radial menu (Wiseman, Lemke. & Hiles,
1969; Callahan, Hopkins, Weiser & Shneiderman, 1988) then appears directly
under the tip of the pen. A user then highlights an item by keeping the
pen pressed and making a stroke towards the desired item. If the item has
no sub-menu, the item can be selected by lifting the pen. If the item does
have a sub-menu, it is displayed. The user then continues, selecting from
the newly displayed sub-menu. Figure 1 (a) shows an example. Lifting the
pen will cause the current series of highlighted items to be selected.
The menus are then removed from the screen. At any time a user can indicate
"no selection" by moving the pen back to the center of the menu before
lifting, or change the selection by moving the pen to highlight another
item before lifting. A user can also "back-up" to a previous menu by pointing
to its center.
The other, faster, way to make a selection without popping up the menu is by drawing a gesture. A gesture can be drawn by pressing the pen down and immediately moving. The shape of the gesture dictates the particular series of items selected from the menu hierarchy. Figure 1 (b) shows an example.
In effect, the menu reveals the commands associated with vocabulary of zig-zag gestures. Figure 2 shows an example of zig-zag gesture vocabulary and the menu that reveals them.
Marking menus adhere to the design principles as follows: Revelation is provided by the pop-up menu (the novice can see what commands are available). Guidance is provided by system giving the user feedback and additional menu items as menu is traversed. Rehearsal is provided by the physical movement involved in selecting an item from the menu being identical to the movement required to make the gesture corresponding to that item.
We have extensively user tested marking menus and have found that they are used as designed. Novices pop-up the menus but with experience learn to use the gesture (i.e., they become experts). Drawing a gesture has been show to be dramatically faster than traditional menu selection techniques. See (Kurtenbach, 1993) for an in-depth analysis of marking menus.
In order to investigate this question we decided to take an existing pen-based application that used iconic gestures and attempt to design an interaction mechanism that would provide revelation, guidance and rehearsal for those gestures. The test bed for this design experiment was an electronic whiteboard application called Tivoli (Pederson, McCall, Moran, & Halasz, 1993). Tivoli is intended to be used in collaborative meeting situations, much in the same way that a traditional whiteboard is used. Tivoli runs on a large vertical display, called Liveboard, that can be written on with an electronic pen. Much like a whiteboard, several people can stand in front of a Liveboard and write, erase, gesture at, and discuss hand drawn items. Handwriting and drawings also can be edited by a combination of direct manipulation commands (i.e. button, menus, etc.) and iconic gestures. Figure 3 shows Tivoli and Figure 4 shows the types of iconic gestures used.

Figure 3: An application called Tivoli, running on Liveboard, emulates a whiteboard but also allows drawings to be edited, saved and restored.
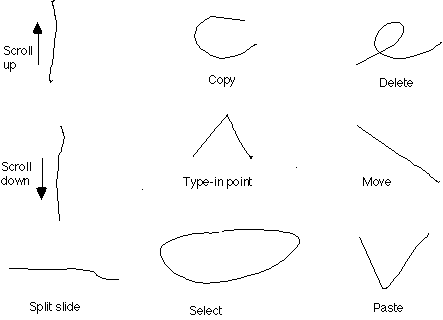
Figure 4: The basic gestures used in Tivoli.
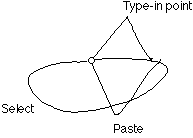
Figure 5: Overlap causes confusion when using the marking menu approach to reveal other types of gestures. Here we display the commands available when starting a gesture from a clear spot in the drawing region of Tivoli.
Not enough information Another problem with a display like Figure
5 is that it gives little contextual information. For example, the important
thing about the "Select" gesture is that it should encircle objects and
the shape of the circle can vary. This type of information is not shown
in Figure 5.
The meaning of several iconic gestures in Tivoli is determined not only by the shape of the gesture but also by the context in which the gesture is made. For example, a straight line over a bullet-point moves an item in a bullet-point list, while a straight line in a margin scrolls the drawing area. These types of inconsistencies can potentially confuse the user. To avoid these problems, we wanted to provide context sensitive information about which gestures a user can make over what objects. Informally, we wanted a user to be able to answer the question: "what gestures can I draw on this object or location?". Since marking menus are sensitive to context (i.e., the contents of a menu may vary depending on where it is popped up), we hoped that some similar mechanism could be designed for iconic gestures in Tivoli.
In general, many characteristics may affect the meaning of a gesture: the shape of a gesture, the direction it is drawn in, the location of features and the dynamics of drawing. These characteristics need to be revealed.
Figure 6 shows the crib-sheet technique we designed for Tivoli. The design works as follows. Similar to a marking menu, if one doesn't know what gestures can be applied to a certain object or location on the screen, one presses-and-waits over the object for more information, rather than drawing a gesture. At this point, rather than a menu popping up as in the marking menu case, a crib-sheet is displayed. The crib-sheet displays the names of the functions that are applicable to the object or location, and example gestures. If this is enough information, a user can draw one of the gestures in the crib-sheet (or take any other action) and the crib-sheet automatically disappears. If the pen is released without drawing a gesture, the crib-sheet remains displayed until the next occurrence of a pen press followed by a pen release or a press-and-wait event.
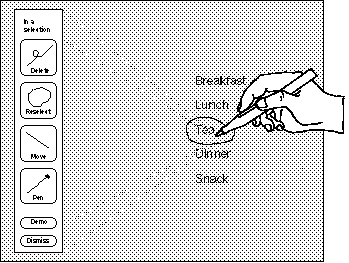
Figure 6: Revealing iconic gestures in Tivoli: The user has selected the word "Tea" by circling it. To reveal what functions can be applied to the selection, the user presses-and-waits within the selection loop. A crib-sheet pops up indicating the context ("In a selection") and the available functions and their associated gestures.
This design has several important features which distinguish it
from a pop-up menu. First, the system displays the crib-sheet some distance
away from the pen tip so that the crib-sheet does not occlude the context.
This leaves room for a user to draw a gesture. Second, a user must draw
a gesture to invoke a command. For example, a user cannot select the delete
button to perform a deletion. The user must draw a delete gesture to perform
a deletion. Finally, the significance of the location of the pen tip is
displayed at the top of the crib-sheet (i.e., in Figure 6 "In a selection"
is displayed at the top of the crib-sheet). This is useful for revealing
the meaning of different locations and objects on the screen.
This design obeys the principles of revelation, guidance, and rehearsal. The crib-sheet provides revelation, and a user can use the examples as guidance when drawing. Rehearsal is enforced because a user must draw a gesture to invoke a command rather than pressing on a crib-sheet item.
Animated, annotated demonstrations While the crib-sheet does reveal contextual information about gestures, it still lacks certain types of information. For example, one static example of a gesture relays little information about variations and features of a gesture. Ideally a demonstration of the gesture in context should be provided, similar to what one receives when an expert user demonstrates a command.
The examples in the crib-sheet could be animated to show how to draw a gesture, variations on a gesture, and the various features of a gesture. However, crib-sheets illustrate gestures outside of the context of the material that the user is working on, and this can make it difficult to see how the gesture applies to the context.
To solve this problem we extended the function of the crib-sheet by adding animations of gestures which take place in context. If the crib-sheet does not provide sufficient information, a demonstration of a gesture can be triggered by pressing the "demo" button on the crib-sheet. The demonstration of the gesture begins at the location originally pressed. The demonstration is an animation of the drawing of the gesture which is accompanied by text describing the special features of the gesture (see Figure 7).
There are several important aspects to this design:
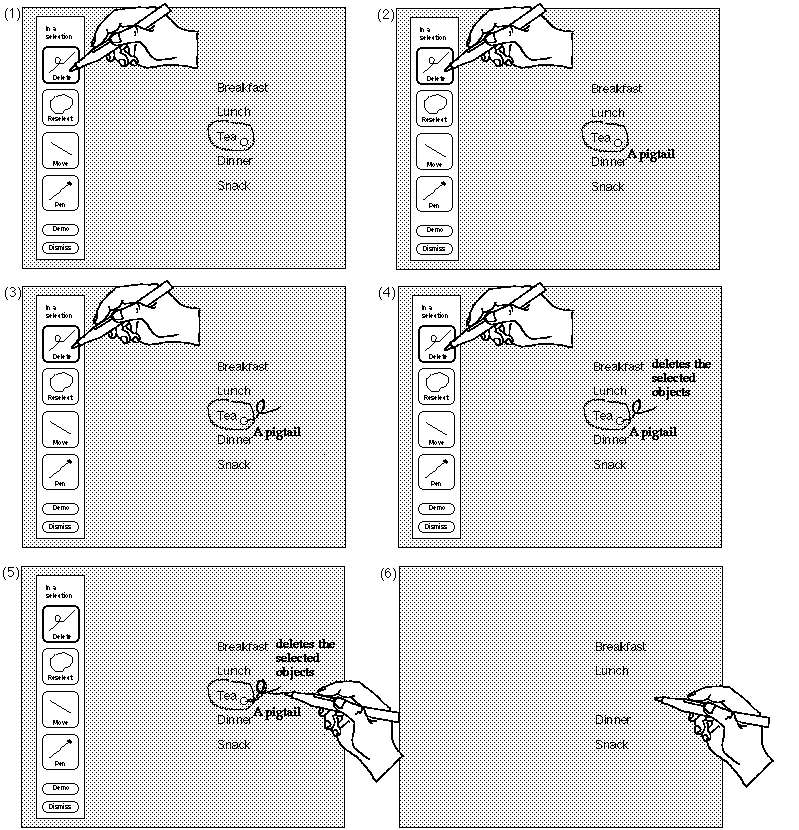
Figure 7: A demonstration of a particular function can be attained by pressing its icon. In (1) the user presses on the delete icon for more information. This triggers an animated demonstration of the gesture with text annotation to explain its features. This is shown in (2), (3) and (4). In (5), the user traces along the example gesture to invoke the function. When the pen is lifted, the action for the gesture is carried out, and the crib-sheet and animation disappear (shown in (6)).
GAD is constructed by first hand-drawing the gesture examples and annotations in Tivoli, then placing these into GAD. Annotations are then labeled by where and when they should occur in the animation cycle (e.g., "start" and "end"). A gesture is a sequence of x and y coordinates which is animated by incrementally displaying the gesture. When animating a gesture the animator uses the same drawing dynamics as the original hand-drawing. In this way, dynamics of drawing can be revealed and the speed of an animation can be controlled by the constructor of the examples. The pacing of the animation of text annotations is determined by length of text: after an annotation is displayed the animator pauses for an amount of time that is proportional to the length of the text before continuing with the rest of the animation. This gives a user time to read the annotation and then watch the rest of the animation.
A key feature to this design is that extra examples of the same gesture can be placed in GAD and tagged for special purposes. If an example is tagged as "variation", the animator animates this example along with the original example of the gesture. In this way, variations on a gesture can be shown to the user. Examples gestures are also used for the crib-sheet buttons.
Multiple examples of gestures also allow the animation of gestures in constrained spaces. For example, assume that a user invokes the animator near the bottom of the drawing area, and that one of the possible gestures at that point is a pigtail (delete). At the bottom of the drawing area, there is no room to draw a pigtail downwards, but there is room to draw it upwards. Thus, the animator only uses examples that will fit in the location. Thus, GAD should be set up with several examples of each gesture, so that the animator can find an example for any location. We found as little as four different examples were sufficient.
Users were also able to make use of the crib-sheet/animator after a brief demo. We found that users explored the interface by pressing-and-waiting at different spots to see what functions where available. We also observed users tracing the animated gestures. The most common error involved a user pressing-and-waiting with the command button pressed, then releasing the button while watching the animation. The user would then trace the animated gesture without the command button being pressed (Tivoli requires a command button on the pen to be pressed for the system to interpret marks as gestures not as drawing or hand-writing). Not having the command button pressed would result in the mark being drawn but not interpreted. We feel this type of error may disappear when a user gets into the habit of holding down the command button to issue a command. It is also possible to have the system recognize this error and advise the user to press the command button.
One problem with our current implementation is that, although animations do appear in context, they do not "work with" the context. For example, the animation of a loop being drawn to select objects sometimes doesn't enclose any objects. The problem is the animator has no knowledge about the Tivoli objects underlying the animation. A more advanced version would extend the notion of parameterized gestures to allow them to utilize and manipulate Tivoli objects in the current working context. This would require a much more sophisticated architecture similar to architecture for parameterizable, context sensitive animated help for direct manipulation interfaces (Sukaviriya & Foley, 1990).
We presented two designs that follow these design principles. Marking menus integrate radial menus and zig-zag gestures. The crib-sheet/animator represents the application of the design principles to any type of gesture. The fact that the crib-sheet animator is a workable design proves that the design principles are generalizable to iconic gestures.
Designing a mechanism to reveal iconic gestures brings to light many issues concerning the revelation of gestures. First, revelation can occur at various levels of detail. The crib-sheet is the first level: a quick glance at the icon for a gesture may be sufficient for the user. An animation is the second level: it requires more time but provides more information and explanation. Our design essentially supports a hierarchy of information where there is a time versus amount of information tradeoff.
A hierarchic view of information can also be applied to the way in which gestures themselves are revealed. For some gestures, it is sufficient just to show a static picture of the gesture. For other gestures an annotated animation is needed before they can be understood. Besides an animation, some gestures need to show variations. Finally some gestures, like menu marks, are best revealed incrementally. Depending on the characteristics of a gesture, there are different ways of explaining the gesture. This implies our revelation schemes must support these different forms of explanation. Marking menus, crib-sheets, and animations are instances of different forms of explanation. A complete taxonomy of forms of explanation is future research.
While user testing is needed to refine our design, we feel that this design supports the desired type of information flow. Users can interactively obtain information on gestures and this information is intended to interactively teach them how to use these gestures like an expert. No pen-based system that we know of supports this type of paradigm.
Callahan, J., Hopkins, D., Weiser, M. & Shneiderman, B. (1988) An empirical comparison of pie vs. linear menus. Proceedings of CHI `88, 95-100
Carroll, J. M, (1985) What's in a name? New York: Freeman.
Gould, J. D., & Salaun, J. (1987) Behavioral Experiments in Handmarks. Proceedings of the CHI + GI '91 Conference on Human Factors in Computing Systems and Graphics Interface, 175-181, New York: ACM.
Kurtenbach, G. (1993) The design and evaluation of marking menus. Ph.D thesis, University of Toronto
Norman, D. A. & Draper, S. W. (1986) User centered system design: New perspectives on human-computer interaction. Hillsdale, NJ: Erlbaum Associates.
Pederson, E. R., McCall, K., Moran, T. P., & Halasz, F. G. (1993) Tivoli: An Electronic Whiteboard for Informal Workgroup Meetings. to appear in Proceedings of the CHI `93 Conference on Human Factors in Computing Systems, New York: ACM.
Robertson, G. G., Henderson, Jr. A. D., & Card S. K., (1991) Buttons as First Class Objects on an X Desktop. Proceedings of UIST '91 Conference, 35-44, New York: ACM.
Shneiderman, B. (1987) Designing the User Interface: Strategies for Effective Human Computer Interaction. Reading Massachusetts: Addison-Wesley.
Sukaviriya, P. & Foley, J. D. (1990) Coupling a UI framework with automatic generation of context-sensitive animated help. Proceedings of the ACM Symposium on User Interface Software and Technology '88, 152-166, New York: ACM.
Wiseman, N.E., Lemke, H.U. & Hiles, J.O. (1969) PIXIE: A New Approach to Graphical Man-machine Communication, Proceedings of 1969 CAD Conference Southhampton, IEEE Conference Publication 51, 463
Wolf, C. G. (1986) Can People Use Gesture Commands? ACM SIGCHI Bulletin, 18, 73-74, Also IBM Research report RC 11867.